Google Summer of Code Contributions
Lorenz Walthert
2017-09-09
This vignette aims to summarize the contributions made to styler through Google Summer of Code 2017.
styler in practice
As a warm-up, we want to provide a few examples of how styler styles code. It’s possible to use different levels of ‘invasiveness’, as described in the help file for the only style guide implemented so far, which is the tidyverse style guide. The style guide in use is passed to the styling function (i.e style_text() and friends) via the style argument, which defaults to tidyverse_style. In addition to this argument, there are further customization options. For example, we can limit ourselves to styling just spacing information by indicating this with the scope argument:
library("styler")
library("magrittr")
style_text("a=3; 2", scope = "spaces")a = 3; 2Or, on the other extreme of the scale, styling spaces, indention, line breaks and tokens:
style_text("a=3; 2", scope = "tokens")a <- 3
2Another option that is helpful to determine the level of ‘invasiveness’ is strict. If set to TRUE, spaces and line breaks before or after tokens are set to either zero or one. However, in some situations this might be undesirable, as the following example shows:
style_text(
"data_frame(
small = 2 ,
medium = 4,#comment without space
large = 6
)", strict = FALSE
)data_frame(
small = 2,
medium = 4, # comment without space
large = 6
)We prefer to keep the equal sign after “small”, “medium” and large aligned, so we set strict = FALSE to set spacing to at least one around =.
Though simple, hopefully the above examples convey some of the flexibility of the configuration options available in styler. Let us for now focus on a configuration with strict = TRUE and scope = "tokens" and illustrate a few more examples of code before and after styling.
styler can identify and handle unary operators and other math tokens:
# Before
1++1-1-1/2# After
1 + +1 - 1 - 1 / 2It can also format complicated expressions that involve line breaking and indention based on both brace expressions and operators:
# Before
if (x >3) {stop("this is an error")} else {
c(there_are_fairly_long,
1 / 33 *
2 * long_long_variable_names)%>% k(
) }# After
if (x > 3) {
stop("this is an error")
} else {
c(
there_are_fairly_long,
1 / 33 *
2 * long_long_variable_names
) %>%
k()
}Lines are broken after ( if a function call spans multiple lines:
# Before
do_a_long_and_complicated_fun_cal("which", has, way, to,
"and longer then lorem ipsum in its full length"
)# After
do_a_long_and_complicated_fun_cal(
"which", has, way, to,
"and longer then lorem ipsum in its full length"
)styler replaces = with <- for assignment, handles single quotes within strings if necessary, and adds braces to function calls in pipes:
# Before
one= 'one string'
two= "one string in a 'string'"
a %>%
b %>%
c# After
one <- "one string"
two <- "one string in a 'string'"
a %>%
b() %>%
c()Function declarations are indented if multi-line:
# Before
my_fun <- function(x,
y,
z) {
just(z)
}# After
my_fun <- function(x,
y,
z) {
just(z)
}styler can also deal with tidyeval syntax:
# Before
mtcars %>%
group_by( ! !!my_vars)# After
mtcars %>%
group_by(!!! my_vars)Contributions to styler during GSOC
High-level analysis
The author, with the help of his mentors,
- opened over 60 issues and closed the majority of them with his own pull requests.
- created more than 60 pull requests to master of which the vast majority were merged.
The activity during GSOC can be grouped as follows:
- Replicating with nested styling the outcomes that were previously achieved with flat styling. This required implementation of the visitor as well as a different serialization method.
-
Adding functionality that is only possible with the nested styling such as indention based on operators (
+,%>%etc.), braces{and(. Also the use of raw indention, allowing for token-dependent re-indention. - Infrastructure changes such as serialized testing, improved performance, creation of mutli-line attributes, code re-factoring, & partially flattening out the nested parse table.
-
Extending with additional functionality that was not there with the flat approach. Examples include styling multiple expressions, token replacement (e.g.
<-for=), line break rules (invasive and non-invasive), token insertion (()in function calls within pipes), RStudio addins, styling of comments, styling of a single file, public API redesign, spacing around more operators (colons, commas, infix operators, bang-bang).
The list above is not comprehensive and covers only the large contributions. Always along with coding, documentation and tests were provided. With regard to the initial proposal, we can say that steps one to four (increase documentation and testing of code, perform all operations on with a nested structure, and fully support the tidyverse style guide) were completed to a large extent and a few points under step five have been implemented too. The remaining points under step five as well as the open issues of the repository indicate the direction of further development of the package.
The tidyverse style guide does not cover all formatting cases, so in particular for function calls, various cases were uncovered and a corresponding issue was opened in the styler repository. Also, it was not possible in this project to implement the rule that forces lines to be less than 80 characters long. We leave this to lintr. Known remaining problems are well-documented on the issue page of the main repository on GitHub. It is nice to see that styler is already getting some traction from the community. The maintainer of the package reprex plans to add styler as a dependency. As soon as one of its dependencies is accepted to CRAN, styler will also be submitted.
Low-level analysis
We can use the package gitsum to perform an analysis of the git repository.
# install.packages("remotes"); remotes::install_github("lorenzwalthert/gitsum")
library("gitsum")
library("tidyverse")
log <- parse_log_detailed() %>%
filter(date > as.Date("2017-06-01"), date < as.Date("2017-08-31"))We see that the vast majority of the commits in this period come from the student and a few from the main mentor.
log %>%
group_by(author_name) %>%
count()# A tibble: 3 x 2
# Groups: author_name [3]
author_name n
<chr> <int>
1 Jon Calder 2
2 Kirill Müller 60
3 Lorenz Walthert 391We can also look at how the number of lines in the different files evolved:
lines <- log %>%
add_line_history()
r_files <- grep("^R/", lines$changed_file, value = TRUE)
to_plot <- lines %>%
filter(changed_file %in% r_files) %>%
group_by(changed_file) %>%
mutate(has_changed = n() > 1) %>%
filter(has_changed)
ggplot(to_plot, aes(x = date, y = current_lines)) +
geom_step() +
scale_y_continuous(name = "Number of Lines", limits = c(0, NA)) +
facet_wrap(~changed_file, scales = "free_y")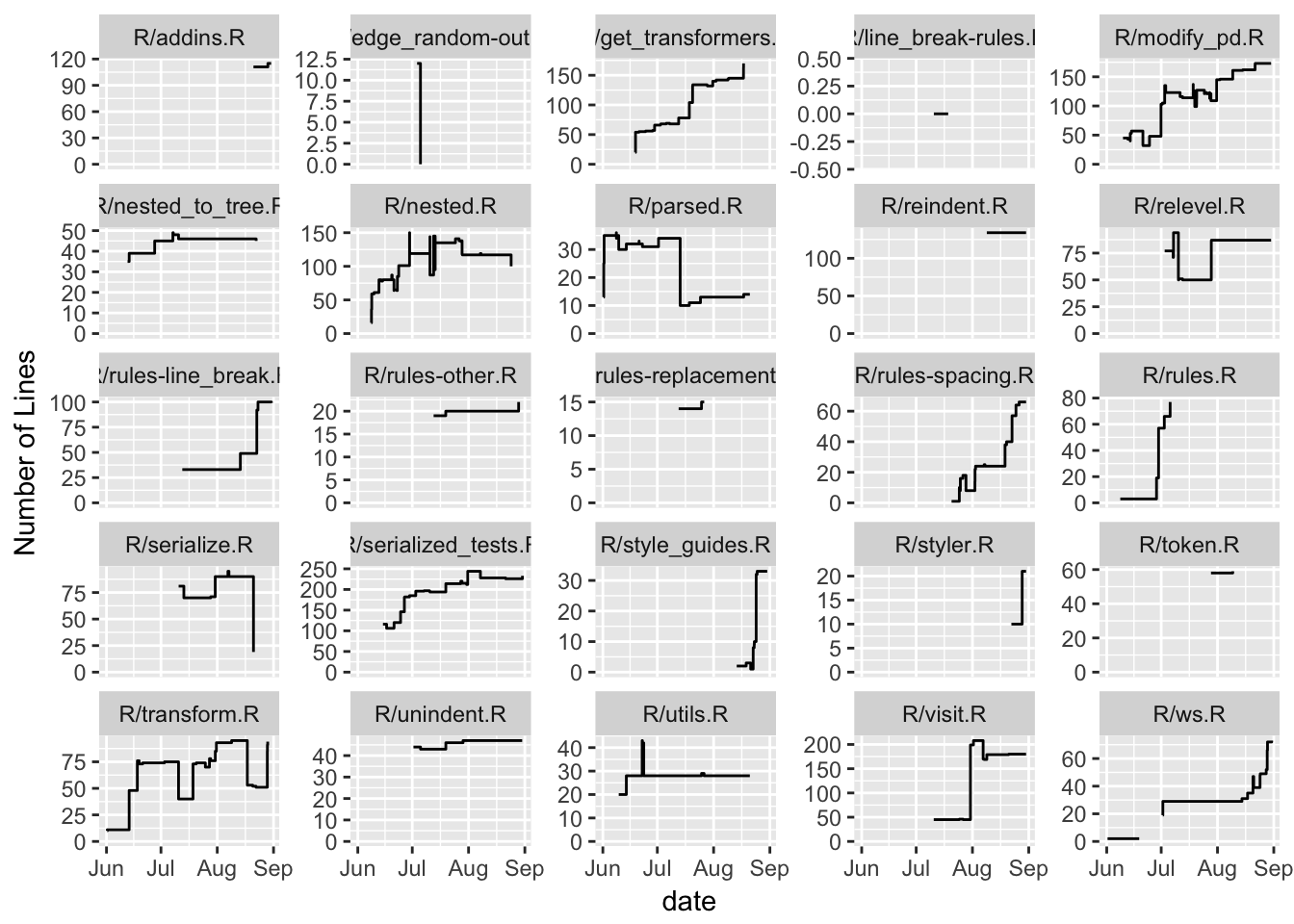
The total number of insertions and deletions by the author is:
log %>%
filter(author_name == "Lorenz Walthert") %>%
summarize(sum(total_insertions) + sum(total_deletions)) %>%
pull()[1] 27015This contains many insertions and deletions in some files that were generated as a by-product of the code changes themselves, so let’s focus on the code in the R directory.
log %>%
unnest() %>%
filter(dirname(changed_file) == "R") %>%
summarize(sum(insertions) + sum(deletions)) %>%
pull()[1] 6180The core code with .R files only consists of:
log %>%
unnest() %>%
filter(grepl("\\.R$", basename(changed_file))) %>%
summarize(sum(insertions) - sum(deletions)) %>%
pull() %>%
cat("lines")4251 linesFinal remarks
First and foremost, I want to thank my mentors, in particular Kirill Müller, for his patience and the time he put into the project. I really appreciate that and I think apart from the code submitted, I benefitted so much from him in terms of how to code, what considerations to make and how to deal with pitfalls and unexpected problems along the way.
In addition, I want to thank Google for their contributions to open source that made this project possible as well as all people involved with organizing GSOC from the R community. It was an amazing experience.